
Real-Time Flood Detection: Achieving Supply Chain Resilience through Large Language Model and Image Analysis 🚗
Floods are a natural disaster that can greatly disrupt supply chain management, particularly logistics where delivery of goods and services will be delayed or completely interrupted. Real-time monitoring and assessment of flood situations are vital to mitigate the loss and damage caused by flood.
Riding the technological wave, we can achieve strides in real-time flood detection by integrating images and geolocation information captured by devices such as cars’ dashboard camera and video surveillance cameras (CCTV) together with Multimodal Large Language Models (LLMs).
Picture this:
A delivery vehicle travels along its designated route with its dashcam capturing real-time images and geolocation data simultaneously together with other data sources including satellite imagery and radar data. The data is fed and analysed by the Multimodal LLMs, the model can accurately describe the images captured, perform analysis with other data to provide a reliable means of detecting the occurrence of floods with geolocation information timely.
How do Multimodal LLMs work with Images for Flood Detection?
Recent research has shown the capability of Multimodal LLMs in image understanding, visual question answering (QVA) and generation of image descriptions. Multimodal LLMs incorporate textual information along with visual data into the learning process by leveraging image and text representations from pre-trained models for both image and text, this allows the model to have a more holistic understanding towards images.
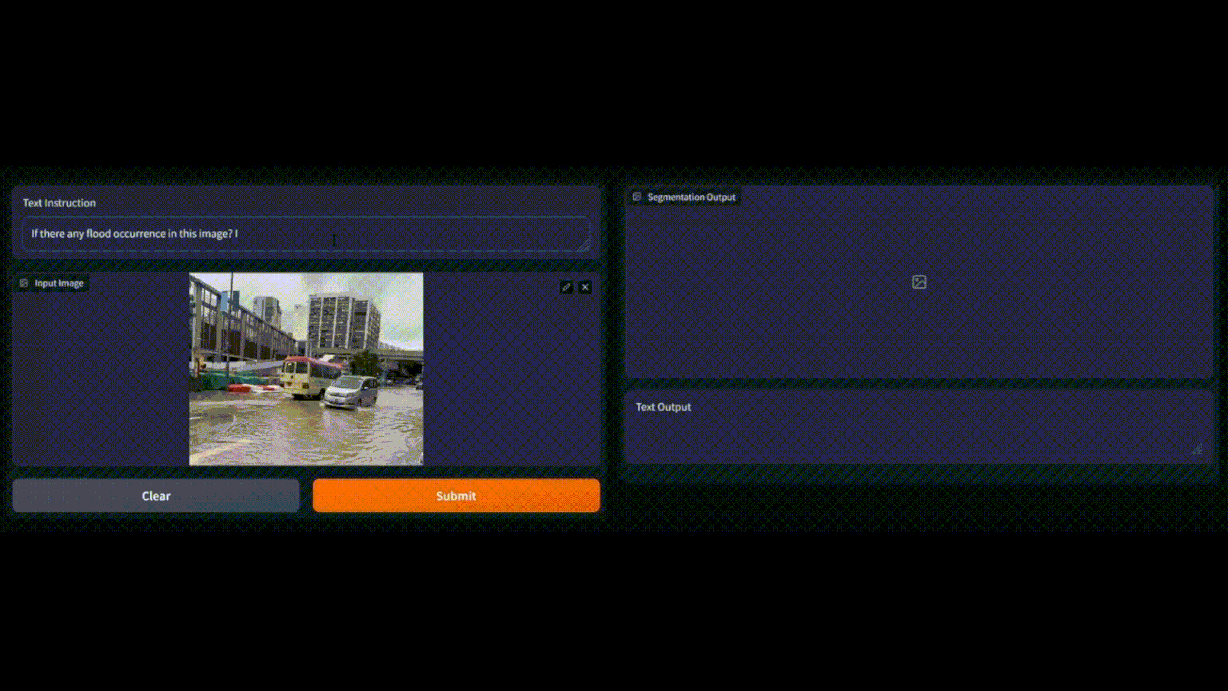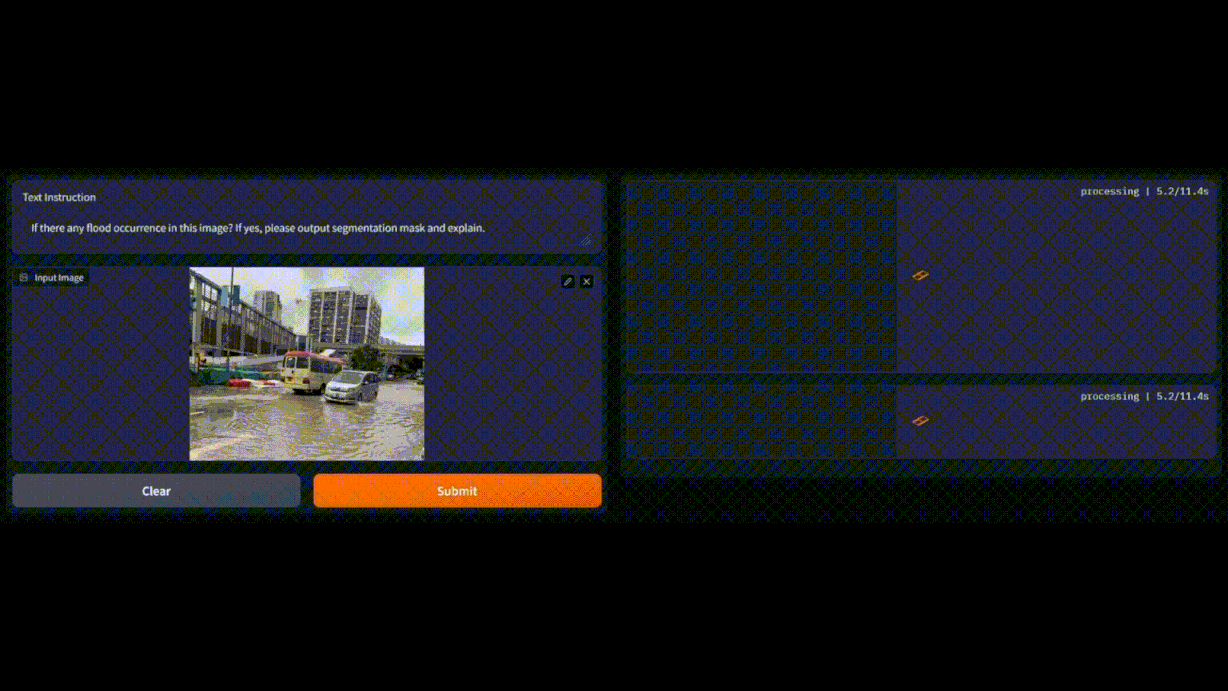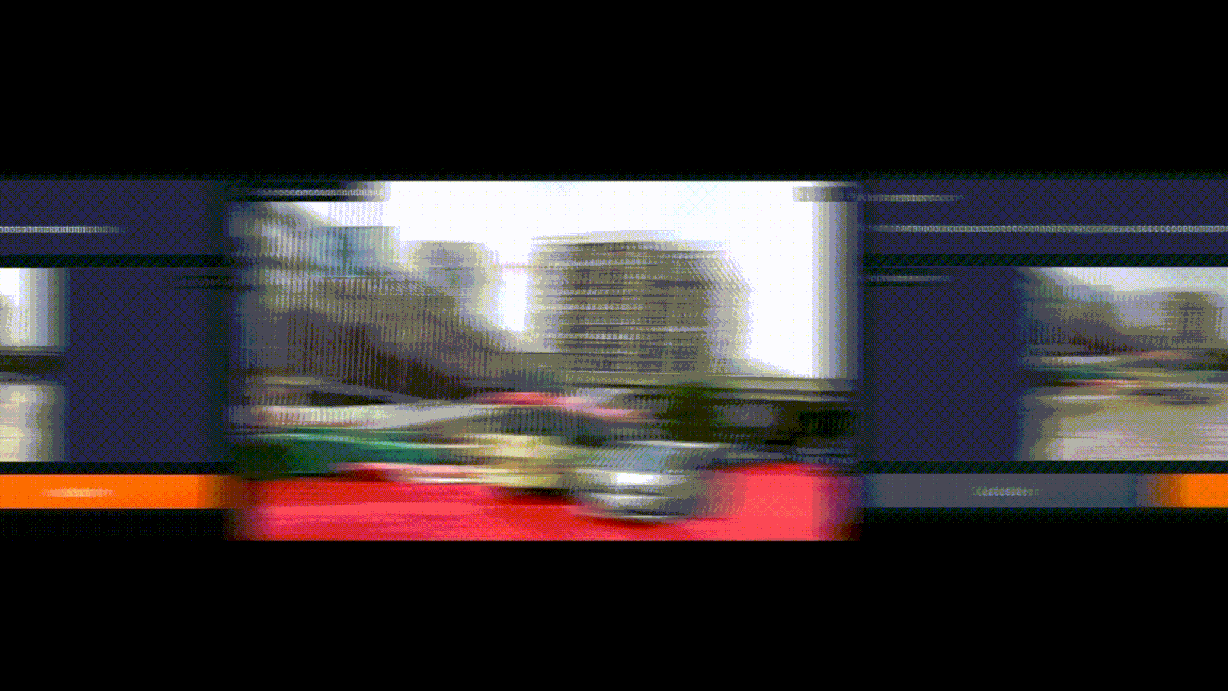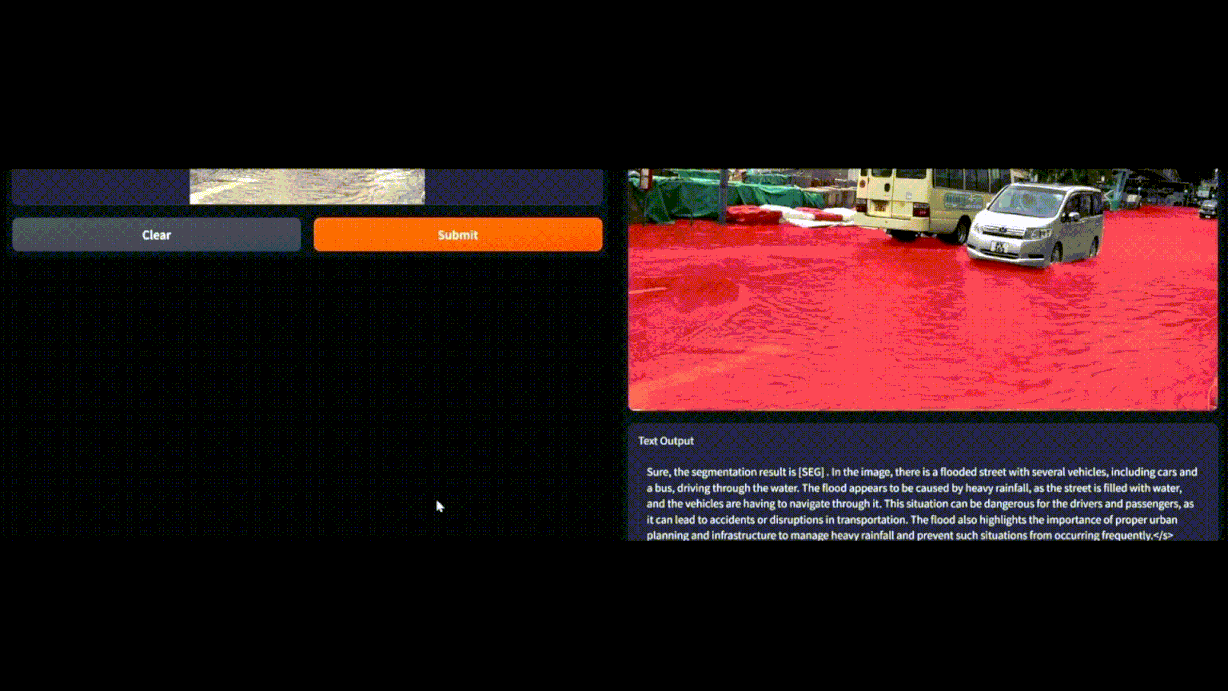
Flood area segmentation with LISA: Reasoning Segmentation via Large Language Model
Previously, flood detection with conventional Artificial Intelligence (AI) models required massive amount of good-quality dataset and extensive training. Conventional AI models face difficulties in comprehending abstract concepts, such as the ambiguity surrounding terms like “flood” and “standing water.” In contrast, Multimodal LLMs are pre-trained on massive corpora of images and texts, thus can perform predictions even without further training or fine-tuning. Furthermore, Multimodal LLMs have shown to be more effective at capturing specific and nuanced concepts, such as the severity level of a flood based on different factors compared to conventional AI model. For example, multimodal LLMs can capture semantic information, such as the height of submerged buildings and vehicles on the road, which can be relevant details in certain scenarios. Hence, multimodal LLMs’ approach in flood detection overcomes the limitations of conventional AI models and has shown its potential in revolutionizing flood detection and response efforts.
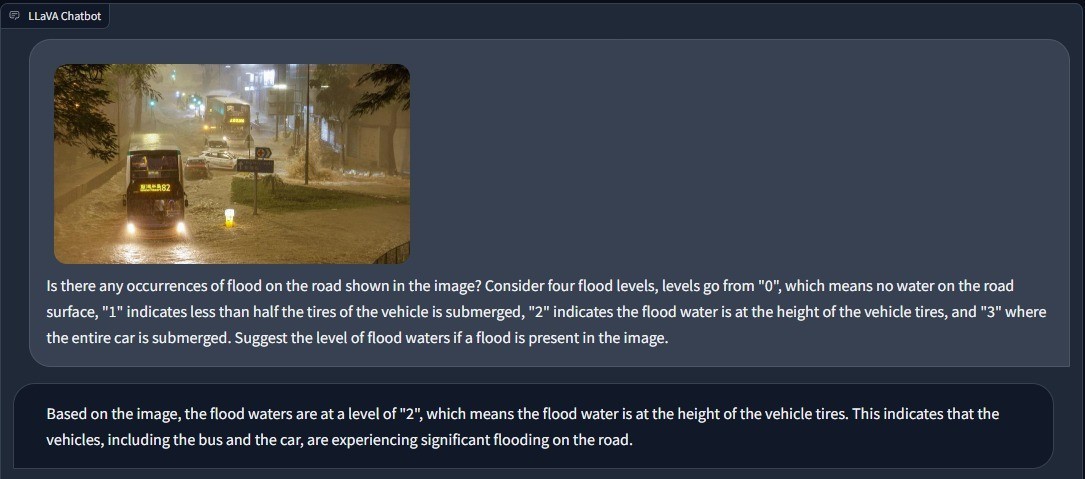
Indication of flood levels using Multimodal LLMs - Llava (Large Language-and-Vision Assistant)
Multimodal LLMs and Supply Chain Resilience
This is game-changing for supply chain management. As we venture further, Multimodal LLM-based flood detection method can even provide immediate route optimization when sufficient data including traffic is present for model training. The model’s ability to handle vast amounts of data enables it to analyse in real-time and suggest potential alternative routes to ward off potential disruptions and ensure that supply chains keep moving with enhanced efficiency. 🚀







