

TL;DR
What: Liger Kernels now run on AMD GPUs, bringing SOTA GPU kernel to ROCm
Key Benefits:
- Up to 26% faster multi-GPU training
- Up to 60% memory reduction
- Support for 8x longer context lengths
- Seamless integration with popular frameworks
Get started with the instructions here!
Introduction
AMD GPUs are stepping up to the challenge of Large Language Model (LLM) training, and Liger Kernels are here to help them shine. We’re excited to share how these state-of-the-art (SOTA) training kernels, developed by LinkedIn, are now available on AMD ROCm, opening up new possibilities for faster and more efficient LLM training.
What are Liger Kernels?
Liger Kernel is a collection of carefully optimized Triton kernels designed specifically for LLM training. Through clever techniques like kernel fusion, in-place replacement, and smart chunking, Liger Kernels help your AMD GPU perform at its best. This means:
- Potentially Faster Training: You might see a boost in your multi-GPU training speeds, with up to a 26% increase in throughput.
- Reduced Memory Usage: Train larger models, experiment with bigger batch sizes and longer context length, potentially reducing memory consumption by up to 60%.
- Perhaps Even Longer Context Length: Explore new possibilities in LLM training, with the potential to handle up to 8x longer context lengths.
- Improved Efficiency for Complex Operations: Liger Kernels optimize common LLM operations such as layer normalization, rotary position embeddings, and cross-entropy loss calculations, potentially allowing for more efficient training of advanced model architectures.
- Easy Integration: With a user-friendly API, Liger Kernels can be easily integrated into existing LLM training pipelines and popular frameworks like Hugging Face Transformers, Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed making it accessible for both casual users and experts.
Liger Kernels on AMD ROCm
We understand you might be curious how these kernels, initially designed for Nvidia, can run smoothly on AMD ROCm. The key is OpenAI Triton. Triton is an open-source, Python-like programming language for writing highly efficient GPU code that is cross-platform. With a small adjustment for AMD GPUs’ warp size, Liger Kernels unlock new potential for LLM training on ROCm.
In this blog post, we take a closer look at how Liger Kernels perform on AMD GPUs, exploring their impact on training and inference for various LLM tasks.
ROCm and the Warp Size Tweak: A Technical Deep Dive
To understand how Liger Kernels were adapted for ROCm, let’s explore the technicalities of GPU programming. Both NVIDIA CUDA and AMD ROCm rely on “warps” for parallel execution. A warp is a group of threads that execute instructions concurrently on a GPU, maximizing efficiency.
The core distinction lies in the warp_size. NVIDIA GPUs typically have a warp_size of 32, while AMD’s MI200 and MI300 GPUs, including the MI300X, use a warp_size of 64. This means an AMD GPU can handle twice the number of threads within a single warp.
Why is this crucial? GPUs have a limit on the total number of threads within a workgroup (a block of threads). For the MI300X, this limit is 1024 threads. To ensure optimal performance, the product of num_warps (number of warps) and warp_size must be less than or equal to 1024.
Since Liger Kernels were initially designed for NVIDIA’s 32-thread warps, a minor adjustment was needed for ROCm compatibility. By reducing the num_warps from 32 to 16, we maintain the balance and allow the kernels to run efficiently on AMD GPUs.
Performance Analysis
To assess the performance of Liger Kernels, we conducted an analysis focusing on six key functions commonly used in LLMs:
- Cross Entropy
- GeGLU
- LayerNorm
- RMSNorm
- RoPE
- SwiGLU
We compared Liger’s performance against the standard Hugging Face kernels in two key areas:
A. Training Performance (Forward and Backward Operations)
Figure 1 presents a side-by-side comparison of memory consumption and speed gains for both sets of kernels during training.
- Memory Efficiency: Liger consistently demonstrates superior memory efficiency across various model configurations. This means you can train larger models or use bigger batch sizes with reduced memory overhead.
- Speed Gains: While the speed improvements vary, Liger generally outperforms Hugging Face kernels, with significant gains in certain scenarios. Notably, Liger excels at handling larger hidden sizes and longer sequence lengths, crucial for complex language tasks.
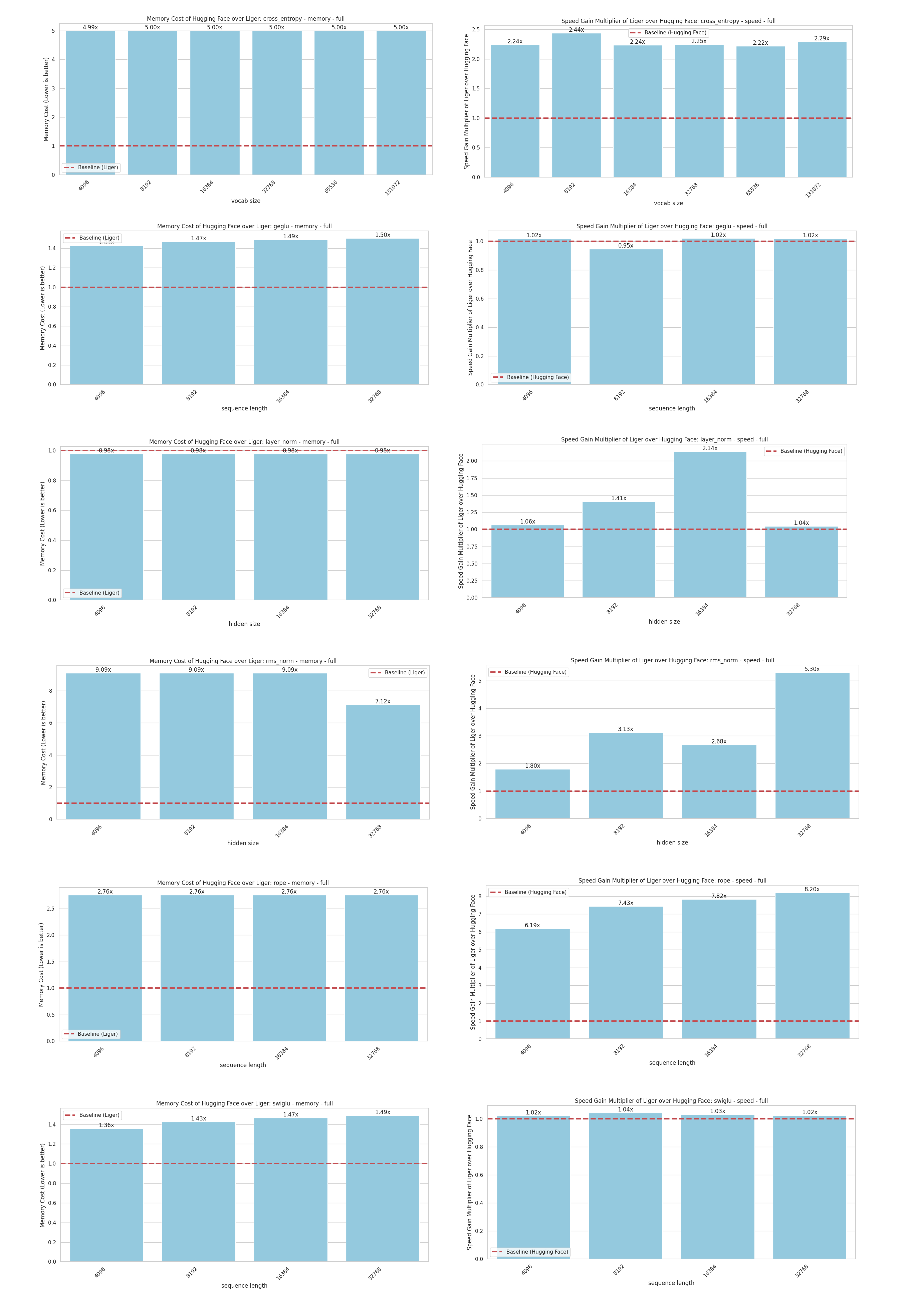
Figure 1: (Left Column) The memory cost of forward and backward operations of the Hugging Face kernel compared to Liger kernel. (Right Column) The speed gain multiplier of forward and backward operations of the Liger Kernel over the Hugging Face kernel.
B. Inference Performance (Forward Operations)
Figure 2 focuses on inference performance, analyzing memory cost and speed gains for forward operations.
- Memory Efficiency: Liger again showcases lower memory consumption across different parameters like vocabulary size, sequence length, and hidden size. This is particularly evident in functions like Cross Entropy, RMSNorm, and RoPE.
- Speed Gains: Liger delivers impressive speed gains, especially with larger vocabulary and hidden sizes. Some configurations, such as Cross Entropy, RMSNorm, and RoPE, see speedups of up to 7.5x!
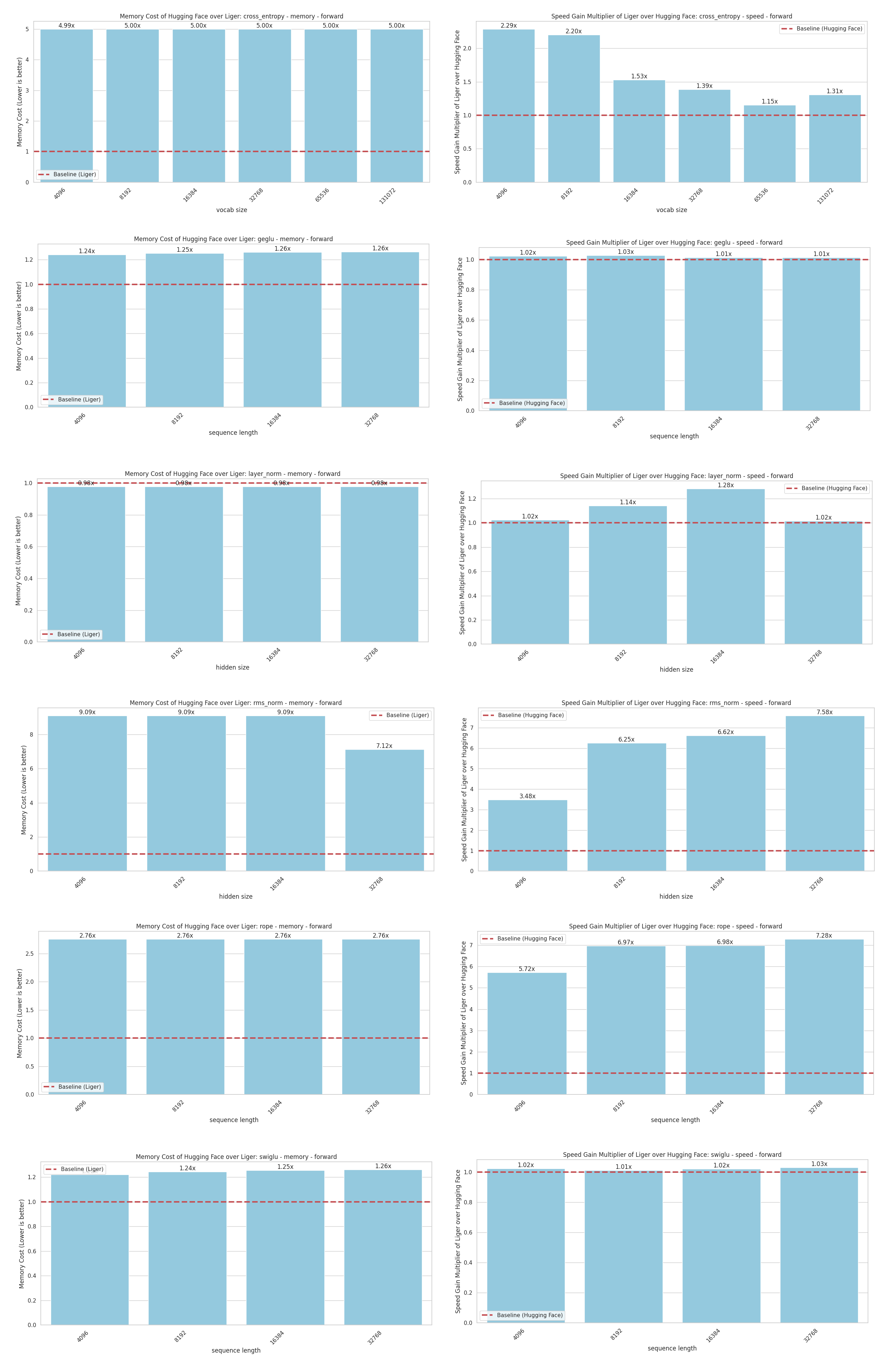
Figure 2: (Left Column) The memory cost of forward operations of the Hugging Face kernel compared to Liger kernel. (Right Column) The speed gain multiplier of forward operations of the Liger Kernel over the Hugging Face kernel.
Real-World Impact: Liger Kernels in Action
To demonstrate the practical benefits of Liger Kernels, we conducted comprehensive benchmarks on real-world LLM training scenarios.
A. Fine-Tuning LLMs with Liger Kernels
Experimental Setup
- Hardware: 4 AMD Instinct MI300X GPUs (192 GB each)
- Models Tested:
- Gemma 7b Instruct
- Llama 3 8B
- Mistral-7B-v0.1
- Qwen2-7B
- Training Configuration:
- Dataset: Alpaca
- Precision: bfloat16
- Sequence Length: 512 tokens
- Optimizer: AdamW with cosine learning rate scheduler
- Measurement: 20 training steps, averaged over 5 runs
- Maximum Batch Size: 512 per GPU (enabled by MI300X’s large HBMe)
Performance Results
| LLM Model | Batch Size | Memory Reduction | Throughput Increase |
|---|---|---|---|
| Gemma 7B Instruct | 64 | 55.27% | 10.3% |
| Llama 3 8B | 128 | 58.96% | 23.4% |
| Mistral 7B v0.1 | 256 | 25.96% | 17.87% |
| Qwen2 7B | 128 | 59.8% | 26.6% |
Detailed Analysis by Model
Gemma 7B Instruct (At Batch Size 64)
- Memory Reduction: 55.27%
- Throughput Improvement: 10.3%
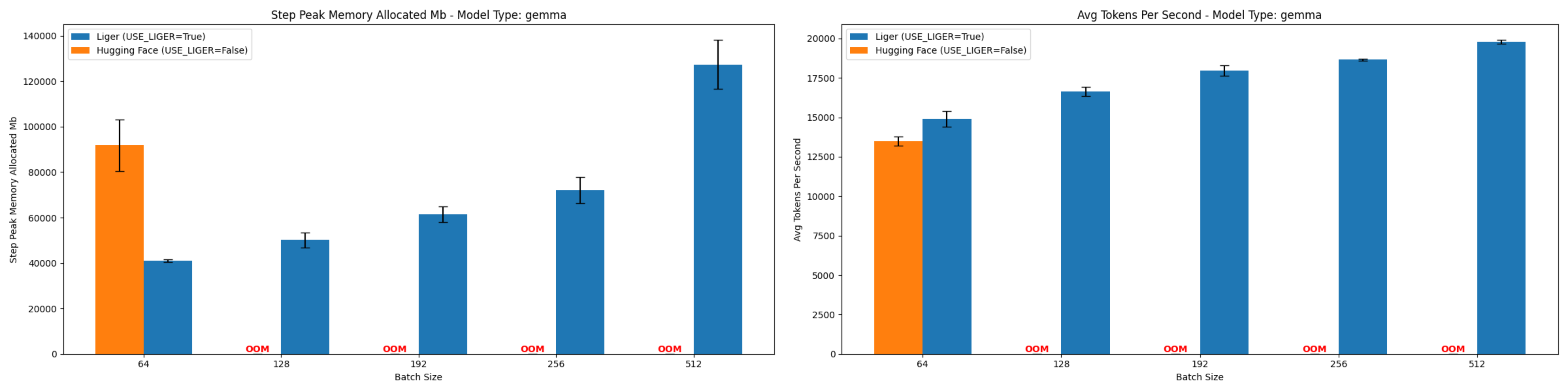
Figure 3: Comparison of peak allocated memory and throughput for Gemma 7b Instruct.
Llama 3 8B (At Batch Size 128)
- Memory Reduction: 58.96%
- Throughput Improvement: 23.4%
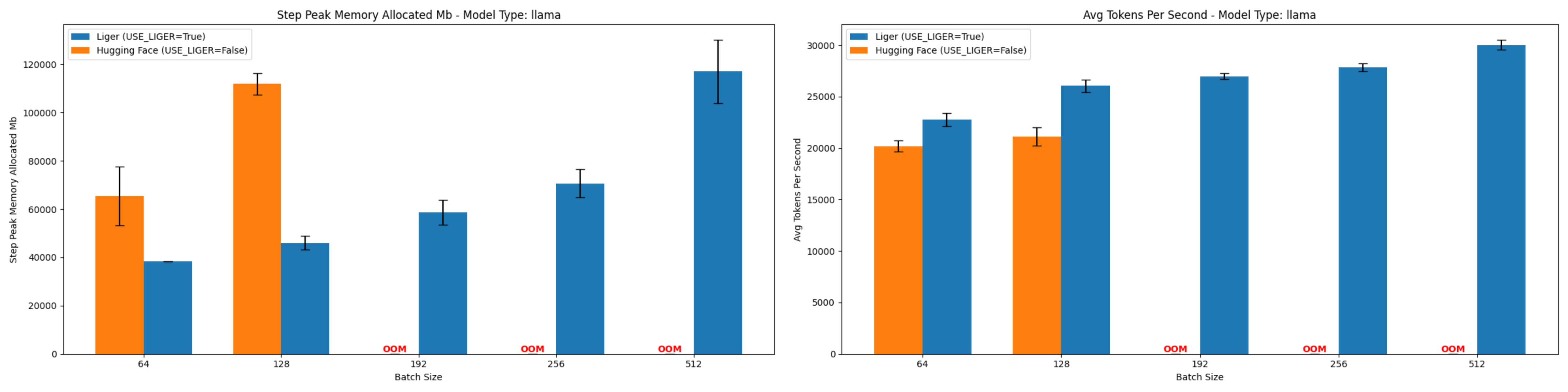
Figure 4: Comparison of peak allocated memory and throughput for Llama 3 8B.
Mistral 7B v0.1 (At Batch Size 256)
- Memory Reduction: 25.96%
- Throughput Improvement: 17.87%
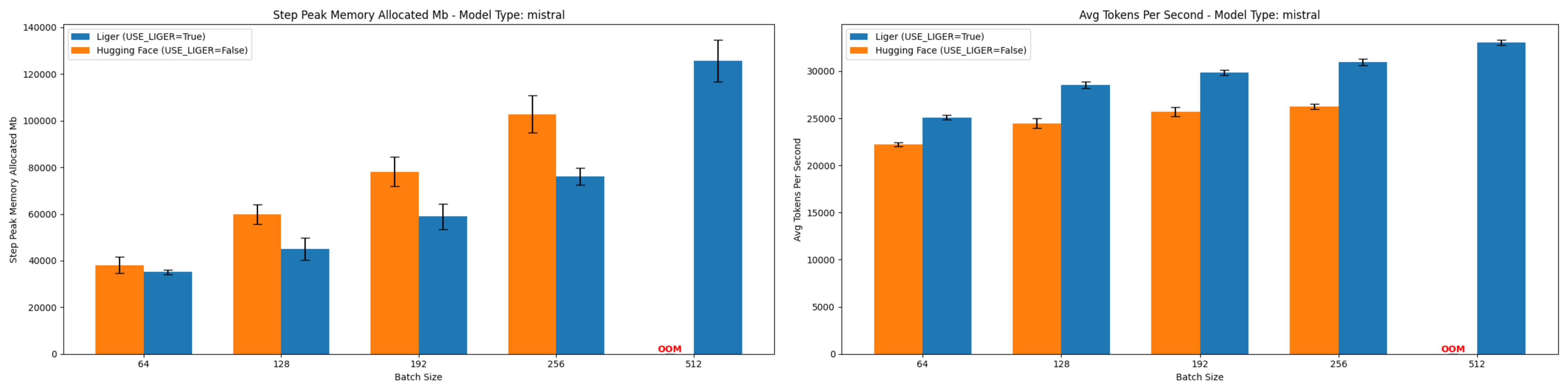
Figure 5: Comparison of peak allocated memory and throughput for Mistral-7B-v0.1.
Qwen2 7B (At Batch Size 128)
- Memory Reduction: 59.8%
- Throughput Improvement: 26.6%
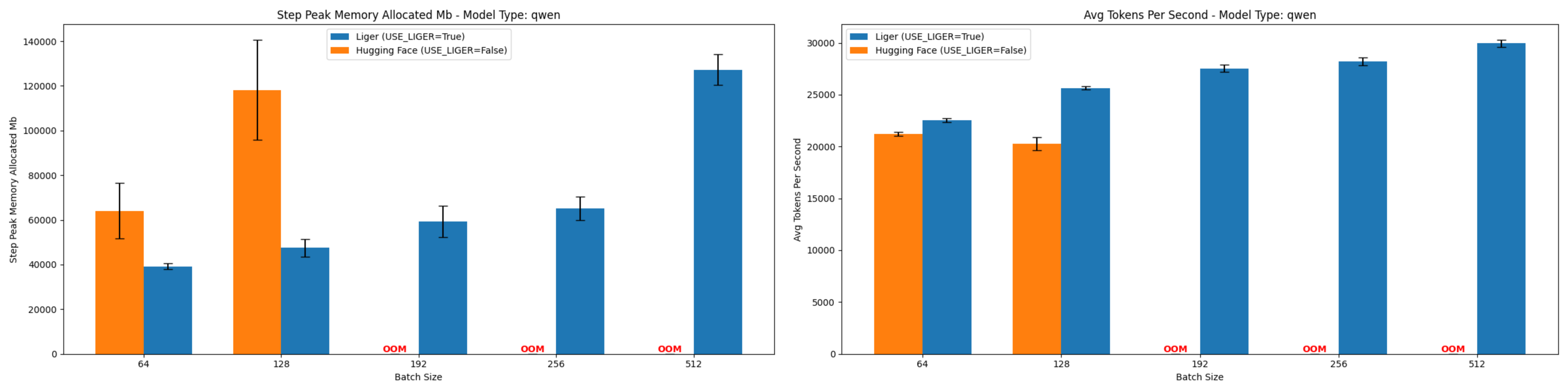
Figure 6: Comparison of peak allocated memory and throughput for Qwen2-7B.
Key Findings
- Memory Efficiency: All models showed significant memory reductions, with Qwen2 7B achieving the highest at 59.8%
- Throughput Gains: Consistent improvements across all models, ranging from 10.3% to 26.6%
- Scalability: Successfully handled large batch sizes up to 512 per GPU
- Consistency: Reliable performance improvements across different model architectures
B. Medusa Speculative Decoding Fine-Tuning
Experimental Setup
- Hardware: 8 AMD Instinct MI300X GPUs (192 GB each)
- Model: LLaMA 3-8B with 1 layer Medusa head
- Dataset: ShareGPT_V4.3_unfiltered_cleaned_split
- Training Configuration:
- Precision: bfloat16
- Training Strategy: FSDP
- Batch Size: 4 per device
- Context Length: Up to 32768 tokens per GPU (Thanks to 192GB MI300X)
- Metrics Collection: After 20 training steps with standard error measurement
Understanding Medusa Heads
Medusa’s architecture uses multiple prediction heads to speculate future tokens. The number of heads determines how many tokens the model predicts simultaneously at each time step. In our experiments, we tested configurations with both 3 and 5 Medusa heads.
Training Stages
The training process consists of two distinct stages:
Stage 1: Focused Head Training
- LLM weights are frozen
- Only Medusa heads are trained
- Results:
- 3 Medusa heads performance metrics
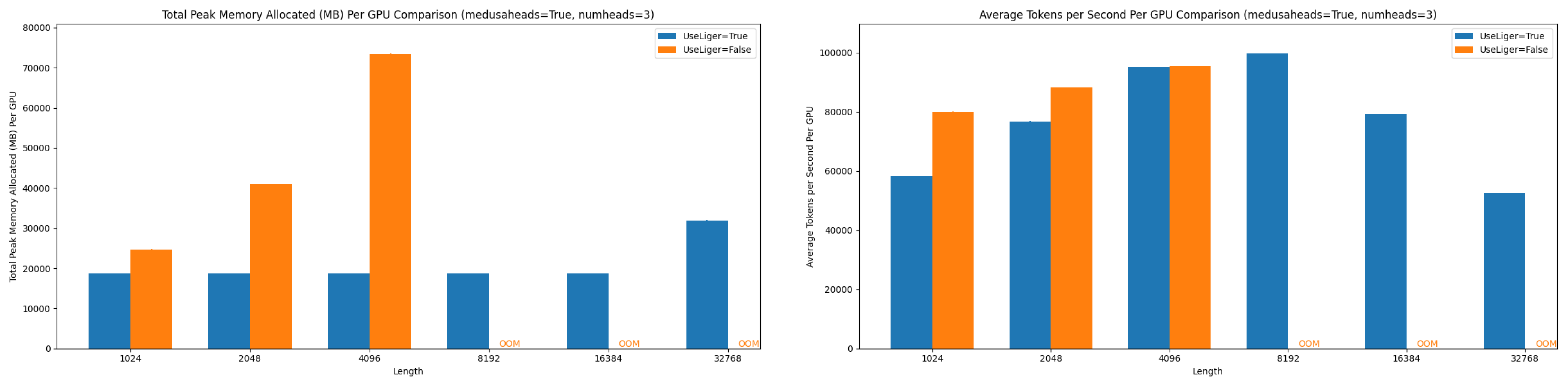
Figure 7: Comparison of peak allocated memory and throughput per GPU in Stage 1 training of 3 Medusa heads Llama-3 8B at various context lengths.
- 5 Medusa heads performance metrics
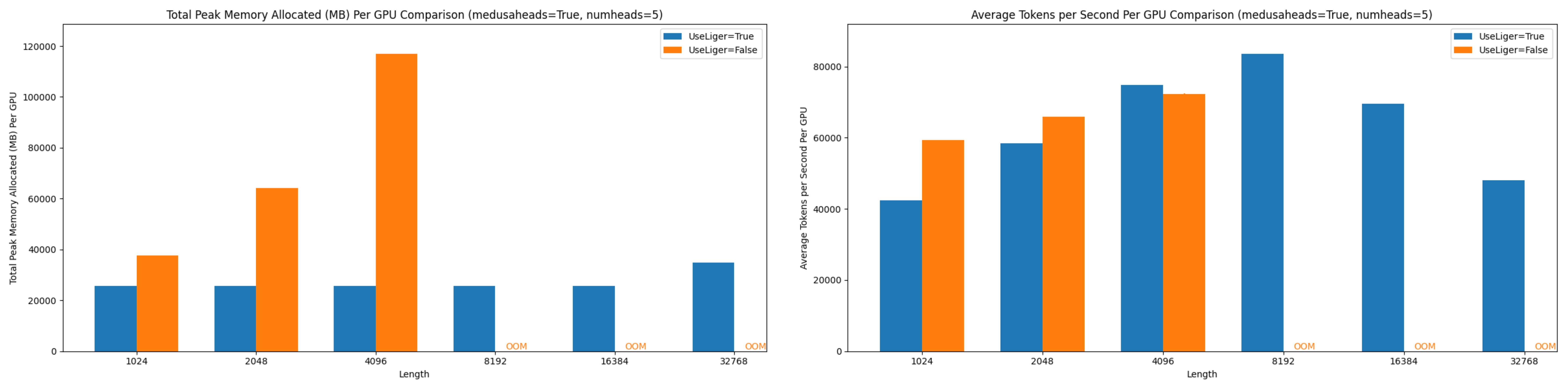
Figure 8: Comparison of peak allocated memory and throughput per GPU in Stage 1 training of 5 Medusa heads Llama-3 8B at various context lengths.
Stage 2: End-to-End Training
- Both LLM and Medusa heads are trained jointly
- Results:
- 3 Medusa heads performance metrics
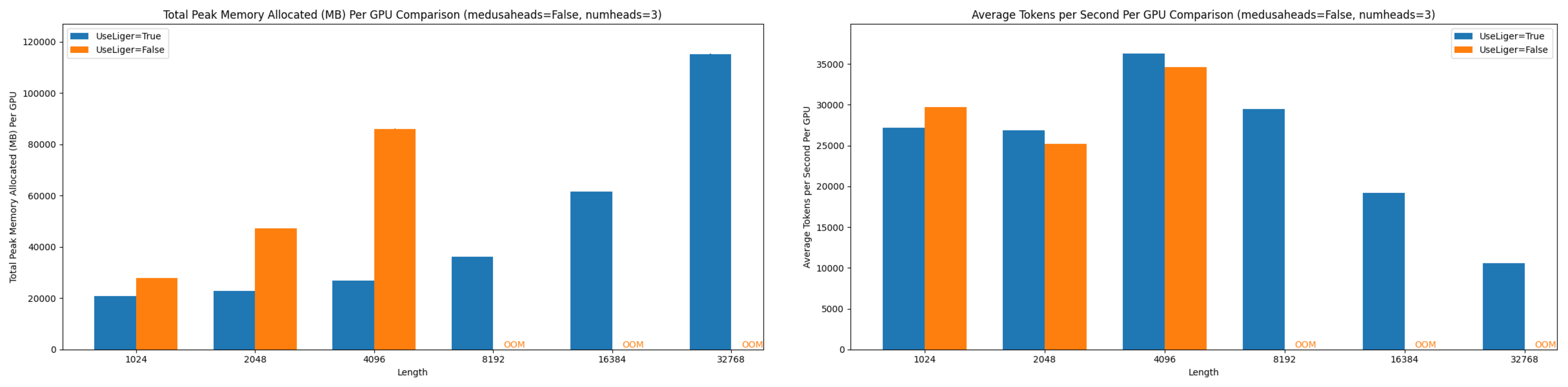
Figure 9: Comparison of peak allocated memory and throughput per GPU in Stage 2 training of 3 Medusa heads Llama-3 8B at various context lengths.
- 5 Medusa heads performance metrics
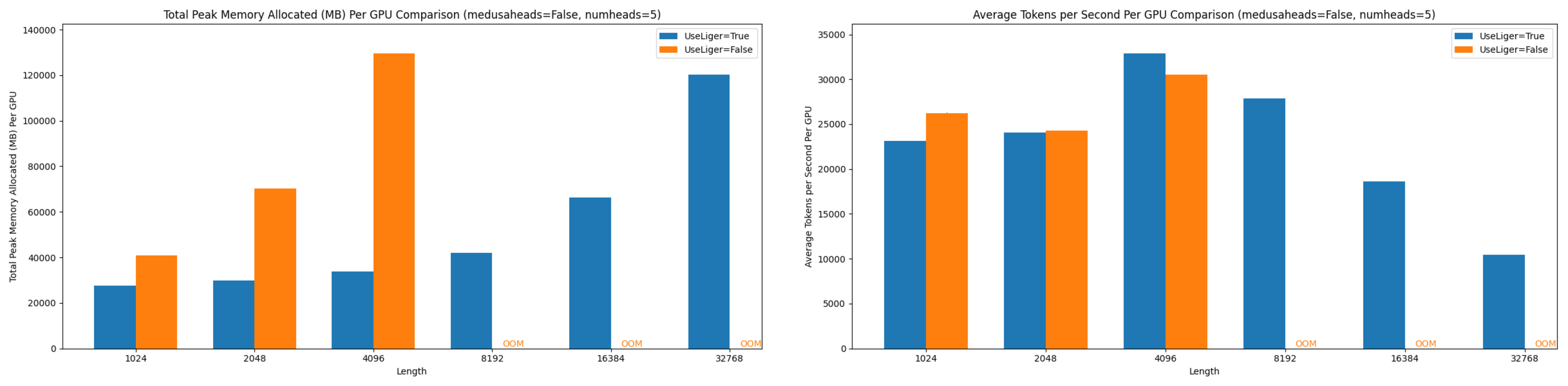
Figure 10: Comparison of peak allocated memory and throughput per GPU in Stage 2 training of 5 Medusa heads Llama-3 8B at various context lengths.
Key Findings
Using Liger Kernel, we observed:
- Significant memory reduction across all configurations
- Ability to handle 8x longer context lengths
- Minimal impact on training speed
- Consistent performance across both training stages
Quick Start
(Cited from the README.md of linkedin/Liger-Kernel)
Install through the following command:
python -m pip install "git+https://github.com/linkedin/Liger-Kernel.git#egg=liger-kernel[transformers]"There are a couple of ways to apply Liger kernels, depending on the level of customization required.
1. Use AutoLigerKernelForCausalLM
Using the AutoLigerKernelForCausalLM is the simplest approach, as you don’t have to import a model-specific patching API. If the model type is supported, the modeling code will be automatically patched using the default settings.
from liger_kernel.transformers import AutoLigerKernelForCausalLM
# This AutoModel wrapper class automatically monkey-patches the
# model with the optimized Liger kernels if the model is supported.
model = AutoLigerKernelForCausalLM.from_pretrained("path/to/some/model")2. Apply Model-Specific Patching APIs Using the patching APIs found in linkedin/Liger-Kernel, you can swap Hugging Face models with optimized Liger Kernels.
import transformers
from liger_kernel.transformers import apply_liger_kernel_to_llama
# 1a. Adding this line automatically monkey-patches the model with the optimized Liger kernels
apply_liger_kernel_to_llama()
# 1b. You could alternatively specify exactly which kernels are applied
apply_liger_kernel_to_llama(
rope=True,
swiglu=True,
cross_entropy=True,
fused_linear_cross_entropy=False,
rms_norm=False
)
# 2. Instantiate patched model
model = transformers.AutoModelForCausalLM("path/to/llama/model")3. Compose Your Own Model
You can take individual kernels to compose your models.
from liger_kernel.transformers import LigerFusedLinearCrossEntropyLoss
import torch.nn as nn
import torch
model = nn.Linear(128, 256).cuda()
# fuses linear + cross entropy layers together and performs chunk-by-chunk computation to reduce memory
loss_fn = LigerFusedLinearCrossEntropyLoss()
input = torch.randn(4, 128, requires_grad=True, device="cuda")
target = torch.randint(256, (4, ), device="cuda")
loss = loss_fn(model.weight, input, target)
loss.backward()Conclusion
Key Achievements
The successful adaptation of Liger Kernels to AMD GPUs represents a significant milestone in cross-platform ML development. With minimal code modifications through Triton, we achieved:
- Up to 26% increase in multi-GPU training throughput
- Up to 60% reduction in memory usage
- Seamless compatibility with AMD ROCm platform
Technical Implementation
Our contribution to make Liger Kernels platform-agnostic has been officially merged into the main repository linkedin/Liger-Kernel:
python -m pip install "git+https://github.com/linkedin/Liger-Kernel.git#egg=liger-kernel[transformers]"If you would like to find out more about Liger-Kernel, checkout their technical report at https://arxiv.org/pdf/2410.10989 .
Acknowledgements
Thank you to ByronHsu from LinkedIn Liger-Kernel Team for reviewing and accepting the PR, and Edenzzzz for reviewing the PR. We would like to extend our appreciation to Hot Aisle Inc. for sponsoring MI300X for Liger-Kernel ROCm development and benchmarking. Thanks for the issue discussion by Edenzzzz and DocShotgun.
References
- Liger-Kernel Technical Report: https://arxiv.org/pdf/2410.10989
- Liger-Kernel Github Repo: https://github.com/linkedin/Liger-Kernel
- Liger-Kernel X: https://x.com/liger_kernel