EmbeddedLLM has ported vLLM to ROCm 5.6, and we are excited to report that LLM inference has achieved parity with Nvidia A100 using AMD MI210.
The Need for High Throughput LLM Inference
Large Language Models (LLMs) are known for their significant memory usage and computational expense. This often results in LLM serving becoming the primary operational cost.
PyTorch works out of the box for LLM serving on AMD GPU. However, we can only achieve a fraction of the throughput of a high throughput LLM serving system. A high throughput LLM serving system, like vLLM, must incorporate the following methods:
- Continuous Batching: boosts throughput by 5 - 10x.
- Paged Attention: 3x the throughput.
As our PagedAttention paper is live, it is time to delve into several key techniques in LLM serving.
— Hao Zhang (@haozhangml) September 13, 2023
The 3 most important and *MUST-KNOW* techniques for a (2023-ish) top-notch LLM serving system:
(1) continuous batching: 5 - 10x throughput improvement,
(2) paged attention: 3x… https://t.co/GE5diT0Zr4
To achieve parity with Nvidia using an AMD GPU, a ROCm port of vLLM must exist.
But why have we chosen AMD for our journey?
Usually the answer is as follow:
- Increase compute availability (the world is in an NVIDIA supply crunch!)
- Economic efficiency reasons
- Avoiding vendor lock-in
From EmbeddedLLM’s perspective, the reasons mentioned above are commonly given when AMD is merely considered as a second source GPU supply. However, we respectfully hold a different point of view and choose to fully commit to AMD, as our objectives perfectly align with AMD’s roadmap.
Why has EmbeddedLLM chosen to go all-in with AMD?
- AMD has all the ingredients to build the future of ubiquitous LLM machines: Imagine devices with low power requirements, like edge devices or laptops, built with the most advanced CDNA3 GPU blocks or AMD Zen 4 CPU blocks. Pair these with high-bandwidth memory (HBM), and you have a setup designed to run LLM everywhere! The icing on the cake? These futuristic devices can be programmed using open software ecosystems (ROCm).
- Always bet on Lisa: We have full confidence in AMD’s ability to execute their roadmap a fact they have demonstrated to the world with the Zen architecture. Based on our experience with ROCm, we can attest that they are capable delivering both the driver and computing stack.
As Andrej Karpathy aptly puts it, “The hottest new programming language is English.” This statement rings true as we stand on the brink of a revolutionary shift in computing. The familiar Von Neumann architecture (akin to a Python program) is being challenged by LLM based natural language agents (like English Language).
We are thrilled to be part of this new era in computing and can’t wait to see where this journey takes us. Our mission is to develop the essential components that will allow these LLM machines to integrate seamlessly into our existing workflows and production processes.
The vLLM port
The porting: vLLM porting to ROCm is on the official roadmap and the are some works from the community.
When we start doing the porting, vLLM is on v0.1.4, currently we only port the code for LLaMA based models. The current port is focus on correctness and not focus on performance yet. Checkout our code here.
We are actively working on the v0.2.1 port and we are actively contributing on other effort on upstreaming our changes. We will update our progress on Github and on this blog. Stay tuned for more update next week.
Performance
We compared three GPUs in our benchmark: Nvidia's A100 and L40, and AMD's MI210. Let's compare the GPU specification:| Performance | NVIDIA A100 80GB SXM (HGX A100) | NVIDIA L40 | AMD Instinct MI210 |
|---|---|---|---|
| GPU Architecture | NVIDIA Ampere | NVIDIA Ada Lovelace | AMD CDNA2 |
| Process Node | TSMC N7 | TSMC N4 | TSMC N6 |
| FP32 | 19.5 TFLOPS | 90 TFLOPS | 22.6 TFLOPs |
| FP16/BF16 Tensor Core | 312 TFLOPS | 181.05 TFLOPS | 181 TFLOPs |
| GPU Memory | 80 GB HBM2e | 48 GB GDDR6 | 64 GB HBM2e |
| GPU Memory Bandwidth | 2039 GB/s | 864 GB/s | 1638.4 GB/s |
| L2 Cache | 40 MB | 96 MB | 16 MB |
| Power | 400 W | 300 W | 300W |
| NVLink/Infinity Fabric Link | 600 GB/sec | N/A | 300 GB/s |
| Form Factor | SXM modules | 2 slot PCIe | 2 slot PCIe |
| Power connector | N/A | 12+4-pin 12VHPWR | 1x8 pin 12V EPS |
| Price* | 2 ~ 2.2x | 1x | 1x |
| Availability | Extremely rare 🦄 | Superseded by L40S | OK (before we publish this) |
Table 1: Comparing specification between NVIDIA A100, L40 and AMD MI210. *Market price before we publish this.
| GPU | Repo |
|---|---|
| Nvidia A100 | vllm-project/vLLM v0.1.4 |
| Nvidia L40 | vllm-project/vLLM v0.1.4 |
| AMD MI210 | EmbeddedLLM/vllm-rocm |
Table 2: Software used in this benchmark.
We executed the benchmark by utilizing the official vLLM script. You can visit our Github page to find the steps necessary to replicate the results.
Throughput benchmark
The benchmark was conducted on various LLaMA2 models, which include LLaMA2-70B using 4 GPUs, LLaMA2-13B using 2 GPUs, and LLaMA2-7B using a single GPU. The tables below present the throughput benchmark results for these GPUs. The first table provides the throughput in terms of tokens per second, while the second table the throughput as requests per minute.
| Throughput Benchmark | L40 | A100 | MI210 |
|---|---|---|---|
| LLaMA2-70B 4 GPU | 399.01 | 629.33 | 436.40 |
| LLaMA2-13B 2 GPU | 491.16 | 730.01 | 595.11 |
| LLaMA2-7B 1 GPU | 532.26 | 757.43 | 718.06 |
Table 3: Throughput Benchmark (tokens/s).
| Throughput Benchmark | L40 | A100 | MI210 |
|---|---|---|---|
| LLaMA2-70B 4 GPU | 49.8 | 79.2 | 54.6 |
| LLaMA2-13B 2 GPU | 61.8 | 91.8 | 74.4 |
| LLaMA2-7B 1 GPU | 66.6 | 94.8 | 90.0 |
Table 4: Throughput Benchmark (requests/min).
The figures below show the throughput of offline inference of 1000 questions in tokens per second and requests per minute, respectively.
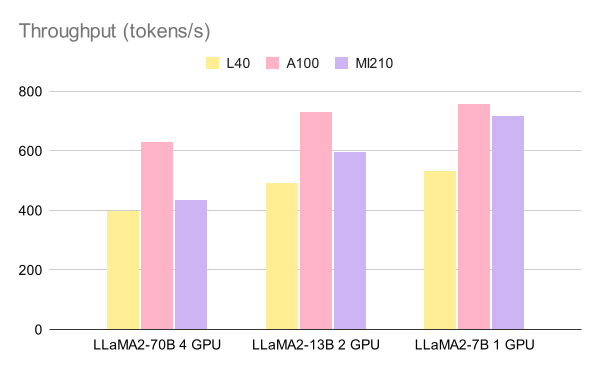
Figure 1: Throughput of offline inference of 1000 question (tokens/s).
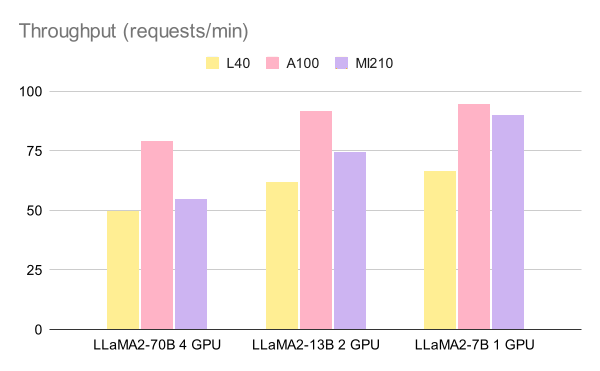
Figure 2: Throughput of offline inference of 1000 question (requests/min).
LLM Serving benchmark
In the realm of server systems, understanding the throughput limit is crucial. This benchmark study aims to investigate the throughput limit of the LLM (Language Learning Model) serving system. The throughput of a server system is directly proportional to the number of user requests it can handle. However, an increase in throughput can adversely affect the latency, leading to a slower response time.
The LLM serving system is no exception. As the number of user requests increases, the throughput also increases. However, there comes a point where the latency starts to increase exponentially without any further increase in throughput. This point is what we refer to.
Our focus in this study is on serving throughput. We have used workloads with different request rates to measure the normalized latency of the systems. The normalized latency is the mean of every request’s end-to-end latency divided by its input and output token length. A high-throughput serving system should ideally maintain a low normalized latency even against high request rates.
The results of our benchmark study are represented in the figures below. The x-axis represents the Throughput (requests/min), and the y-axis represents the Average latency per token (s). The curve that is on the bottom right represents the highest performing serving system.

Figure 3: Serving LlaMA2-7B with 1 GPU

Figure 4: Serving LlaMA2-13B with 1 GPU

Figure 5: Serving LlaMA2-70B with 4 GPU
Future works
As we continue to push the boundaries of LLM inference with AMD, we have several exciting developments lined up for the future.- Benchmark on MI250X: MI250X boasts 2x memory bandwidth and capacity compared to Mi210. This will provide us with valuable insights into the performance enhancements that can be achieved with this advanced hardware.
- Benchmark on MI300A: We can’t wait to be impressed by the speedup of the “King of APU”, Mi300A, with unified memory architectures. This will allow us to understand this technology in improving the efficiency and speed of LLM inference.
- Port the latest vLLM: We are in the process of porting the latest vLLM v0.2.1.post1 and removing dependency on xformers. This will involve upstreaming the changes, which is a crucial step in ensuring that our work is accessible and beneficial to the wider community. Preliminary result shows that vllm-rocm v0.2.1 is 2x faster on MI210 compared to the current benchmark.
- Support more models: This will broaden the scope of our work and make it applicable to a wider range of use cases.
- Performance Optimization: While our current port is primarily focused on correctness, we recognize the importance of performance in a high throughput LLM serving system.
We are excited these upcoming developments and look forward to sharing our progress with you. Stay tuned for more update next week on our Github and this blog. As we continue to innovate and push the boundaries of what’s possible in LLM, we are confident that we are paving the way for the future of computing.
If you need advice on your enterprise LLM deployment, don’t hesitate to contact us. Our team is dedicated to helping you navigate the complexities of LLM deployment and providing guidance and support to ensure your enterprise can leverage the power of LLM. We look forward to sharing our progress with you and helping you achieve your goals.