

JamAI Base is a collaborative spreadsheet platform designed to simplify AI development. Imagine the familiarity and ease of use of a spreadsheet combined with the power of LLMs. With JamAI Base, users can seamlessly build and deploy AI solutions without needing extensive coding expertise.
At the heart of JamAI Base’s innovation lies the Generative Table. This groundbreaking feature reimagines the traditional spreadsheet, transforming it into an AI powerhouse. Imagine a database table that not only stores data but also:
- Autonomously generates content: Simply provide a table title and column names, and the Generative Table uses AI to automatically populate the cells with relevant content. Need a table of marketing ideas for different product categories? Just create the table structure, and JamAI Base will do the rest.
- Extracts information from images: Upload an image, like a receipt or invoice, into a cell, and the AI will intelligently extract structured information based on the column names. For example, it can automatically identify and fill in “shop name,” “category,” “total,” and “tax” from a receipt image.
- Handles complex AI workflows effortlessly: Chain columns together to orchestrate complex AI tasks like RAG and LLM interactions, all without writing a single line of code. This allows you to build sophisticated AI workflows with the simplicity of a spreadsheet.
- Enables multi-agent interaction: Facilitate dynamic interactions between multiple AI agents within the table format, again without any coding. This opens up new possibilities for collaborative AI applications.
- Instantly creates a real-time REST API: With a single click, turn your Generative Table into a live API endpoint, allowing other applications to access and interact with your AI-powered data.
The Generative Table is a game-changer for AI development, making it more accessible, intuitive, and powerful than ever before. It’s like having a team of AI experts built right into your spreadsheet.
The Power of Embeddings
The Generative Table truly redefines how we interact with and leverage AI. But to unlock its full potential, especially for tasks like semantic search and knowledge retrieval, a robust backend system is essential. This is where the embedding computation comes into play. This crucial workflow empowers JamAI Base to understand and utilize enterprise data effectively.
Here’s a closer look at this process:
- Feature Extraction: Imagine teaching JamAI Base to “read” and understand the meaning of your data. This is achieved by processing text and images to extract meaningful features or “embeddings.” These embeddings are like numerical representations that capture the essence and context of the information.
- Knowledge Base Creation: Think of this as building a well-organized library for JamAI Base. Vast amounts of information from various sources are ingested, processed, and stored in a specialized database called a “vector database.” This allows for efficient retrieval of relevant information whenever needed.
- Retrieval Augmented Generation (RAG): This is where the magic happens. By combining LLMs with the knowledge base, JamAI Base can generate accurate, factual, and contextually relevant responses. When you ask a question, the system retrieves relevant information from the knowledge base using the extracted features and uses it to augment the LLM’s understanding, resulting in more insightful and comprehensive answers.
The Challenge of Scale
This workload is computationally intensive, especially when dealing with massive datasets and complex queries. Imagine a company with millions of documents, images, and customer records. To build a knowledge base that can effectively power semantic search or answer complex questions, each piece of data needs to be processed and transformed into a meaningful embedding. This requires immense computational power, especially when dealing with high-dimensional data and complex embedding models. Traditionally, such workloads have been relegated to GPUs, but their cost and availability can be limiting factors.
The Shift Towards CPU-Powered Embeddings
While GPUs excel at parallel processing, their high cost and limited availability can be a barrier, especially for organizations with budget constraints or existing CPU-centric infrastructure. This led JamAI Base to explore the potential of CPUs for handling embedding models, seeking a more cost-effective solution without compromising performance.
This exploration led us to Intel OpenVINO, a powerful open-source toolkit designed to optimize AI inference on Intel hardware. OpenVINO unlocks the capabilities of Intel CPUs, enabling them to handle demanding AI tasks with impressive efficiency.
Here’s what we discovered when we ported our embedding service to support the OpenVINO backend on Intel Xeon CPUs:
- Significant Performance Boost: We observed an 8x speed increase in our Knowledge Base creation workload. This means we can process and embed information much faster, accelerating the development and deployment of AI applications.
- OpenVINO’s Edge: On Xeon 4th generation processors, OpenVINO outperformed the ONNX runtime by approximately 3x in speed and throughput, showcasing its superior optimization capabilities.
- Xeon 6: A Game Changer: When we moved to Intel Xeon 6th generation servers, the results were even more remarkable. We achieved comparable performance to an A10 GPU in document embedding workloads. This was a pivotal finding, demonstrating that CPUs, when optimized with OpenVINO, can rival or even surpass GPUs in specific AI tasks.
The Impact:
This shift to CPU-powered embeddings has several key advantages:
- Cost Efficiency: By utilizing existing CPU infrastructure, we can avoid the need for expensive GPUs, leading to significant cost savings.
- Resource Optimization: Offloading embedding tasks to CPUs frees up GPUs for other critical tasks like LLM serving, maximizing the efficiency of our hardware investments.
- Scalability: CPU-based embedding workloads scale effectively with increasing data sizes, making them a more sustainable solution for large-scale applications.
“After migrating our embedding model from ONNX CPU to OpenVINO on Intel Xeon 6, we witnessed an ~8x acceleration in Knowledge Base creation workload. This enhancement let us free up GPUs for LLM serving, as the Xeon 6 delivers embedding performance on par with the NVIDIA A10 GPU.”
- Tan Pin Siang, CTO of Embedded LLM
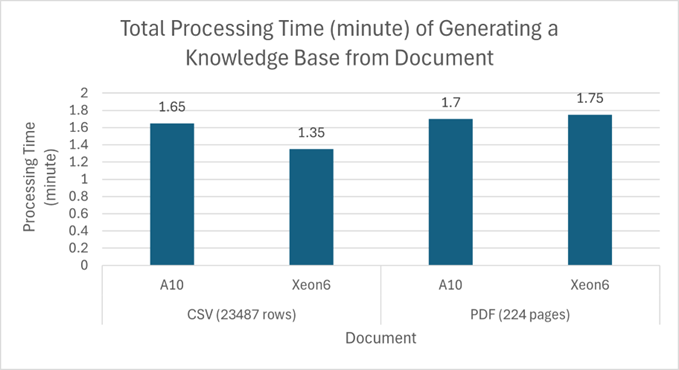
Figure 1: The total processing time using CPU Xeon6 with OpenVINO backend is able to achieve on-par performance to A10 GPU in embedding our document workload.
To further illustrate the impressive performance gains achieved by utilizing Intel Xeon CPUs and OpenVINO for embedding models, we conducted a series of benchmarks. These benchmarks provide concrete evidence of the efficiency and speed improvements observed when running these workloads on optimized Intel hardware.
Benchmarking the Performance
To solidify our observations about the performance advantages of using Intel Xeon CPUs and OpenVINO for embedding models, we conducted a comprehensive set of benchmarks. These benchmarks provide concrete evidence of the efficiency and speed improvements observed when running these workloads on optimized Intel hardware.
Optimum-Intel and OpenVINO: A Powerful Duo
Before diving into the benchmark results, let’s briefly explain the tools that made this performance possible:
- Optimum-Intel: This serves as a bridge between popular machine learning libraries (like Transformers and Diffusers) and Intel’s optimization tools. It simplifies the process of optimizing AI models for Intel hardware by providing an easy-to-use interface for tasks like model optimization, OpenVINO format conversion, and inference execution.
- Intel OpenVINO: This open-source toolkit is specifically designed to optimize AI inference on Intel hardware (CPUs, GPUs, and specialized accelerators). It provides a suite of tools for model optimization, including compression techniques, and allows for conversion of models to its Intermediate Representation (IR) format for efficient inference.
Benchmark Setup
Here’s a detailed overview of our benchmark setup:
Hardware:
- 4th Gen Intel Xeon: Intel(R) Xeon(R) Platinum 8468
- 6th Gen Intel Xeon: Intel® Xeon® 6960P
Software: - OpenVINO 2024.5
Experimental Setup: - Model: BAAI/bge-m3
- Input Data: Random String with specific input tokens length of 400, 1400,2400
- Batch size: 1, 2, 4, 8, 16, 32, 64, 128, 256
- Repetitions: 5 repetitions for each configuration
- Metric:
- 99th Percentile Embedding Time (second)
- Mean Tokens Throughput (tokens/second)
Benchmark Script
For complete transparency and reproducibility, here’s the Python script we used to conduct the benchmarks:
import requests
import random
import string
import time
import csv
from statistics import mean, median
from tabulate import tabulate
from alive_progress import alive_it
# Configuration
OPENAI_API_URL = "http://localhost:17992/embeddings"
MODEL = "BAAI/bge-m3"
BATCH_SIZES = [1, 2, 4, 8, 16, 32, 64, 128, 256] # Different batch sizes to benchmark
TEXT_LENGTHS = [400, 1400, 2400] # Fixed text lengths to test
REPETITIONS = 5 # Number of repetitions for each length
RAW_DATA_FILE = "benchmark_raw_data_infinity_optimum.csv"
STATISTICS_FILE = "benchmark_statistics_infinity_optimum.csv"
# Function to generate random text
def generate_random_text(length):
return ''.join(random.choices(string.ascii_letters + string.digits + ' ', k=length))
# Function to send embedding request
def send_embedding_request(texts):
headers = {
"Content-Type": "application/json",
}
data = {
"input": texts,
"model": MODEL, #Replace with the appropriate model name
}
response = requests.post(OPENAI_API_URL, json=data, headers=headers)
return response
# Benchmark function
def benchmark_embeddings(batch_sizes, text_lengths, repetitions, raw_data_file, statistics_file):
with open(raw_data_file, 'a', newline='') as raw_file:
raw_writer = csv.writer(raw_file)
raw_writer.writerow(["Batch Size", "Text Length", "Repetition", "Time (seconds)", "Status Code", "Prompt Tokens", "Total Tokens", "Tokens Throughput (tokens/second)"])
with open(statistics_file, 'w', newline='') as stats_file:
stats_writer = csv.writer(stats_file)
stats_writer.writerow(["Batch Size", "Text Length", "Mean Time (seconds)", "Median Time (seconds)", "99th Percentile Time (seconds)", "Mean Tokens Throughput (tokens/second)"])
table_data = []
for batch_size in alive_it(batch_sizes):
for text_length in text_lengths:
times = []
tokens_throughputs = []
for repetition in range(repetitions):
print(f"Doing batch_size: {batch_size}, text_length: {text_length}, repetition: {repetition}")
texts = [generate_random_text(text_length) for _ in range(batch_size)]
start_time = time.time()
response = send_embedding_request(texts)
end_time = time.time()
elapsed_time = end_time - start_time
# Extract usage information from the response
usage = response.json().get('usage', {})
prompt_tokens = usage.get('prompt_tokens', 0)
total_tokens = usage.get('total_tokens', 0)
# Calculate tokens throughput
tokens_per_second = total_tokens / elapsed_time
raw_writer.writerow([batch_size, text_length, repetition, elapsed_time, response.status_code, prompt_tokens, total_tokens, tokens_per_second])
times.append(elapsed_time)
tokens_throughputs.append(tokens_per_second)
# Calculate statistics
mean_time = mean(times)
median_time = median(times)
percentile_99_time = sorted(times)[int(0.99 * len(times))]
mean_tokens_throughput = mean(tokens_throughputs)
# Collect statistics for table
table_data.append([
batch_size,
text_length,
f"{mean_time:.4f}",
f"{median_time:.4f}",
f"{percentile_99_time:.4f}",
f"{mean_tokens_throughput:.2f}"
])
# Write statistics to file
stats_writer.writerow([batch_size, text_length, mean_time, median_time, percentile_99_time, mean_tokens_throughput])
# Print table
headers = [
"Batch Size",
"Text Length",
"Mean Time\n(seconds)",
"Median Time\n(seconds)",
"99th Percentile\nTime (seconds)",
"Mean Tokens\nThroughput\n(tokens/second)"
]
print(tabulate(table_data, headers=headers, tablefmt="grid", stralign="right", numalign="right"))
# Run the benchmark
if __name__ == "__main__":
benchmark_embeddings(BATCH_SIZES, TEXT_LENGTHS, REPETITIONS, RAW_DATA_FILE, STATISTICS_FILE)
4th Gen Intel Xeon: Intel(R) Xeon(R) Platinum 8468
There are 6 types of deployment settings being evaluated in this section.
- ONNX FP16 Optimized model weight
- OpenVINO BF16 Inference
- OpenVINO FP16 Inference
- OpenVINO FP32 Inference
- OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference
- OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference
Key Observation:
- The fastest deployment settings are OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference and OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference
- This is because OpenVINO is able to utilize Intel AMX_512 instruction set which are specialized in Matrix Multiplication and the BF16 computation is faster than FP16 computation.
- The INT4 weight quantization makes model weight loading faster into the register for computation. Figure 1 and Figure 2 show that at batch size 256 input token length of 2400 shows that INT4 weight quantization improves the performance up to approximately 2x.
- Should you pick INT4 Weight Only Quantization (Symmetrical) or OpenVINO with INT4 Weight Only Quantization (Asymmetrical) see here.
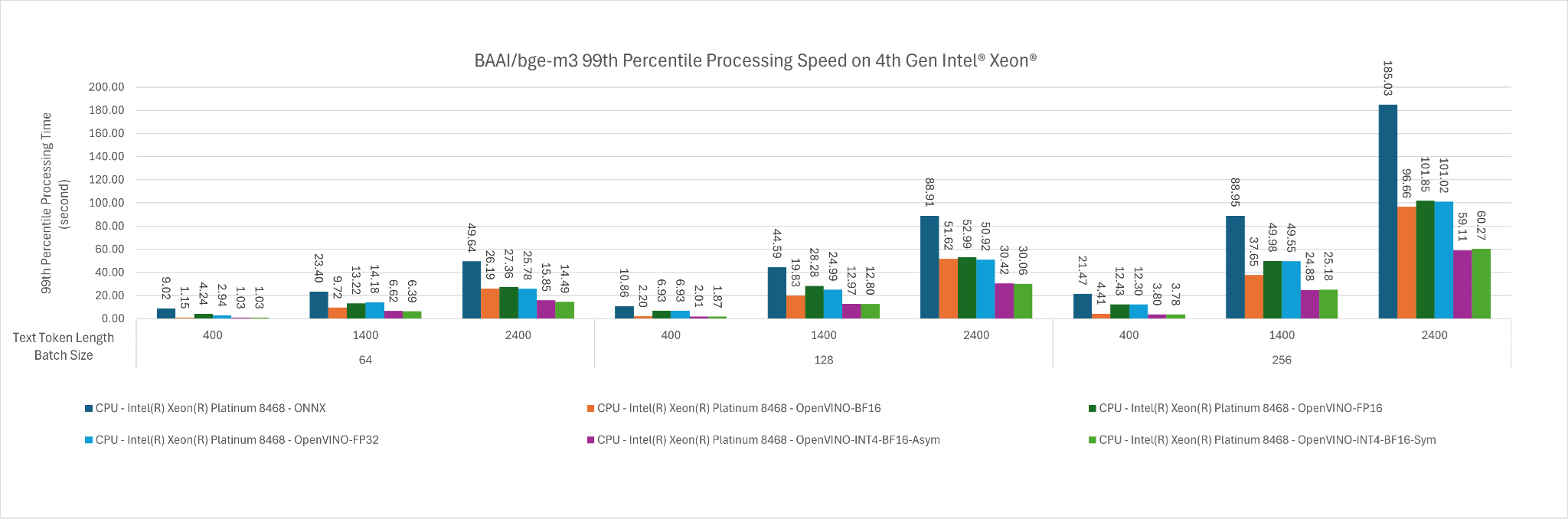
Figure 2: The 99th percentile processing time of BAAI/bge-m3, in seconds, across input token length of 400, 1400, 2400 for batch size 64, 128 and 256.
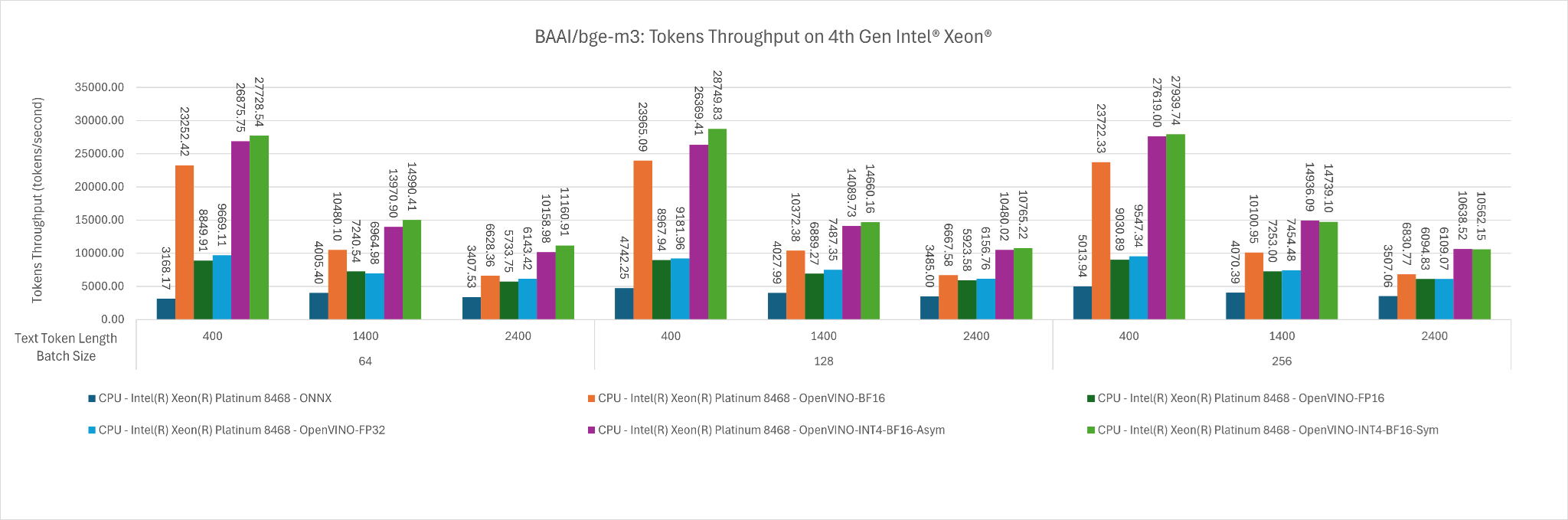
Figure 3: The mean tokens throughput of BAAI/bge-m3 across input token length of 400, 1400, 2400 for batch size 64, 128 and 256.
6th Gen Intel Xeon: Intel® Xeon® 6960P
There are 7 types of deployment settings being evaluated in this section.
- ONNX FP16 Optimized model weight
- ONNX INT8 Weight Quantization with FP16 Optimized Inference (uses Intel® AVX-512 VNNI (Vector Neural Network Instructions))
- OpenVINO BF16 Inference
- OpenVINO FP16 Inference
- OpenVINO FP32 Inference
- OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference
- OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference
Key Observation:
- Same as the observation that we found on 4th Gen Intel Xeon, the fastest deployment settings are OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference and OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference
- This is because OpenVINO is able to utilize Intel AMX_512 instruction set which are specialized in Matrix Multiplication and the BF16 computation is faster than FP16 computation.
- The INT4 weight quantization makes model weight loading faster into the register for computation. Figure 1 and Figure 2 show that at batch size 256 input token length of 2400 shows that INT4 weight quantization improves the performance up to approximately 2x.
- Should you pick INT4 Weight Only Quantization (Symmetrical) or OpenVINO with INT4 Weight Only Quantization (Asymmetrical) see here.
- Additional observation is that OpenVINO generally is faster than ONNX runtime including ONNX INT8 Weight Quantized Model.
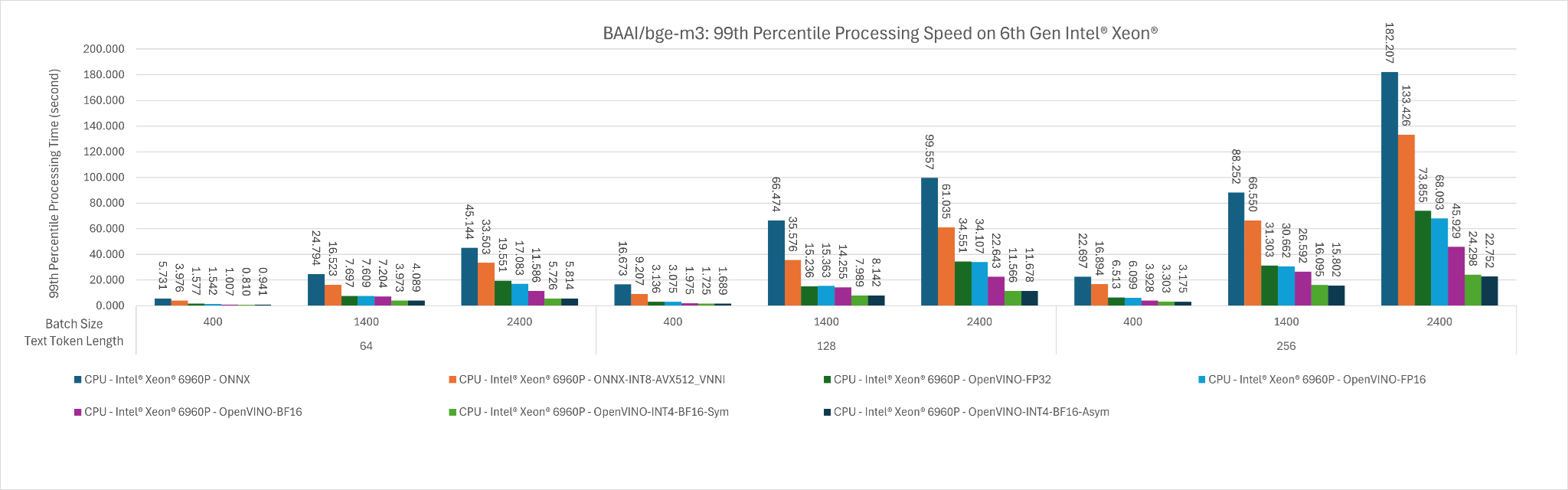
Figure 4: The 99th percentile processing time of BAAI/bge-m3, in seconds, across input token length of 400, 1400, 2400 for batch size 64, 128 and 256.
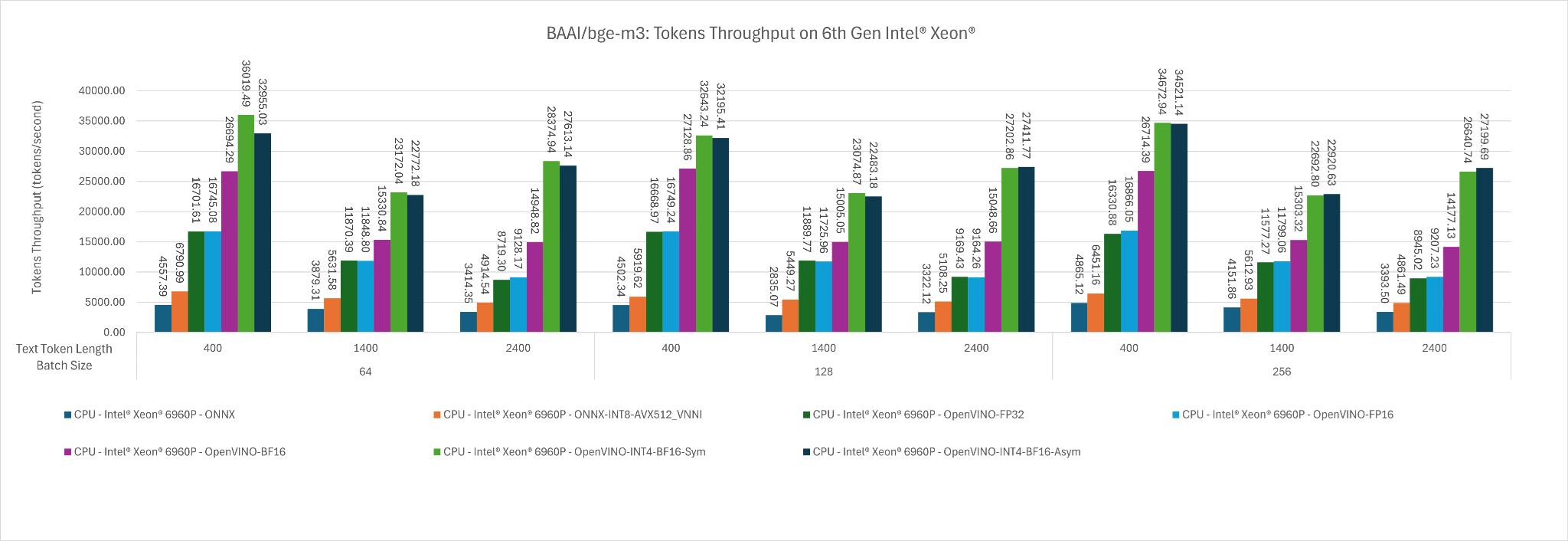
Figure 5: The mean tokens throughput of BAAI/bge-m3 across input token length of 400, 1400, 2400 for batch size 64, 128 and 256.
6th Gen Intel Xeon v.s. 4th Gen Intel Xeon
Now let’s take a look at how much faster is 6th Gen Intel Xeon over 4th Gen Intel Xeon
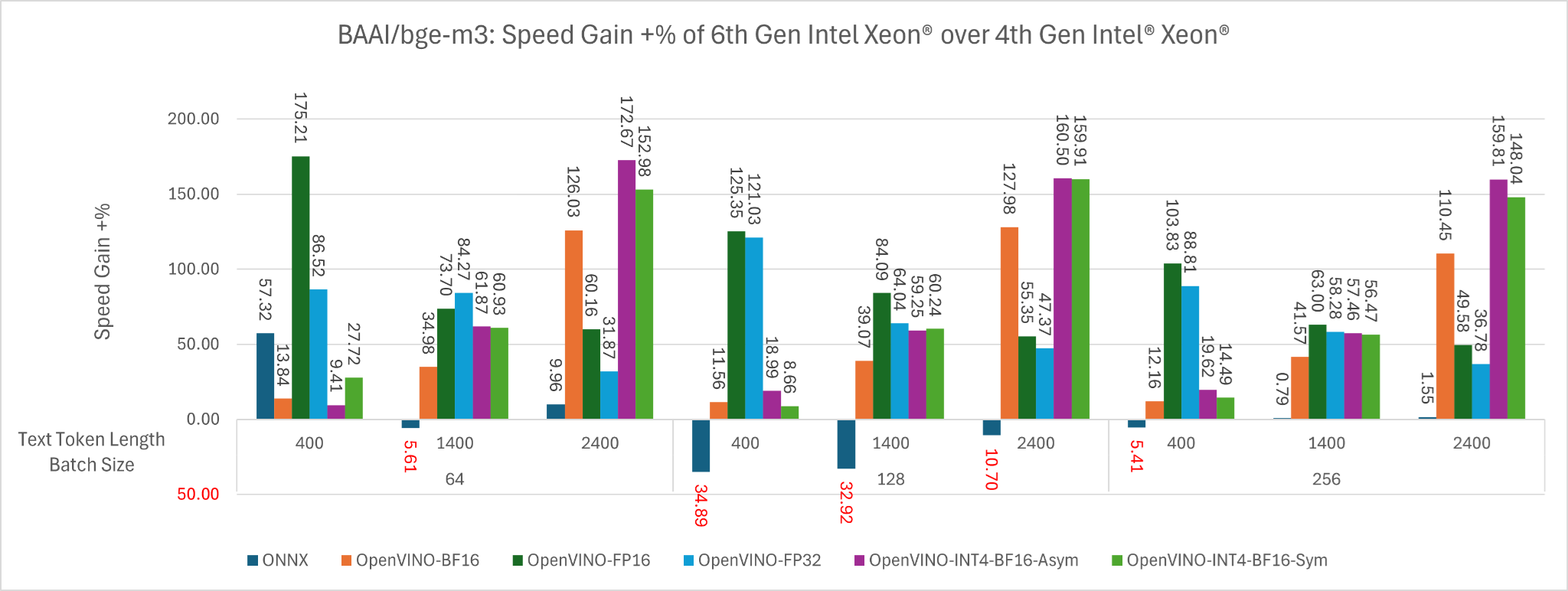
Figure 6: The speed gain +% of 6th Gen Intel Xeon over 4th Gen Intel Xeon across input token length of 400, 1400, 2400 for batch size 64, 128 and 256 for different backend.
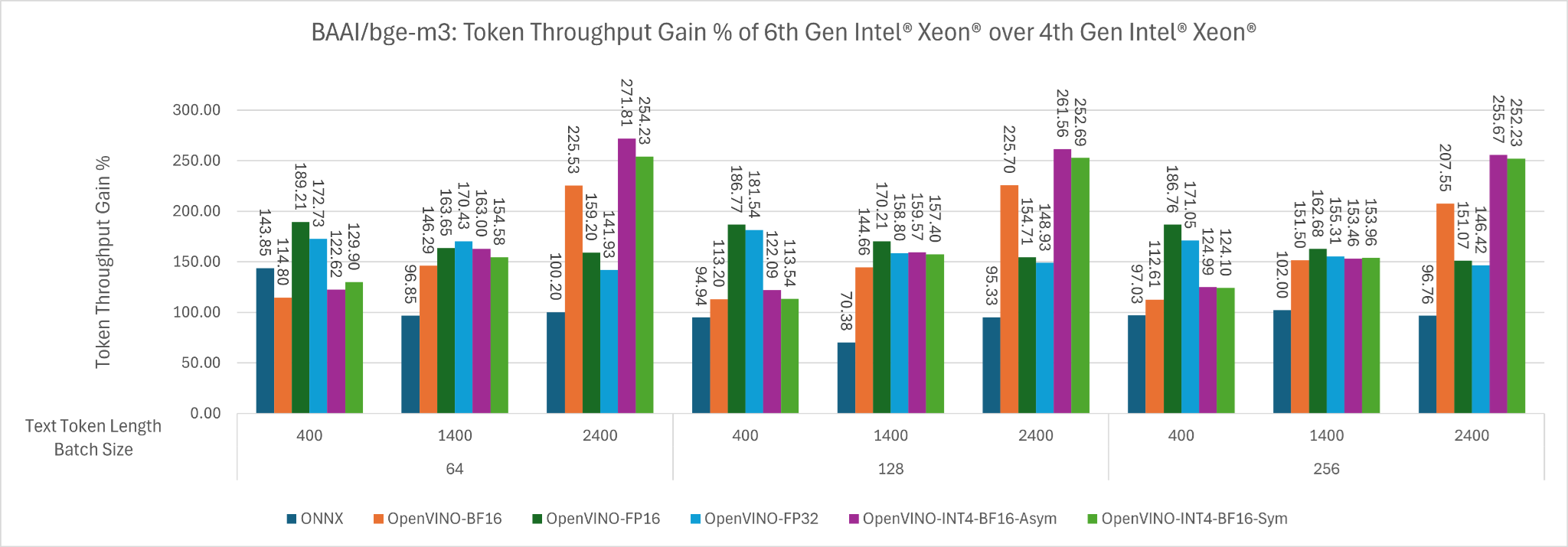
Figure 7: The Token Throughput Gain % of 6th Gen Intel Xeon over 4th Gen Intel Xeon across input token length of 400, 1400, 2400 for batch size 64, 128 and 256 for different backend.
MTEB Benchmark - Bankclassification
The speed gain using OpenVINO with INT4 weight only quantization is as large as 271% at long context length (e.g. 2400). What is the tradeoff in accuracy? We did a small and quick validation evaluation of the embedding model on the bankclassification dataset from the MTEB Benchmark.
- The accuracy of the OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference drops only by 1%
- The accuracy of the OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference drops only by 0.71%
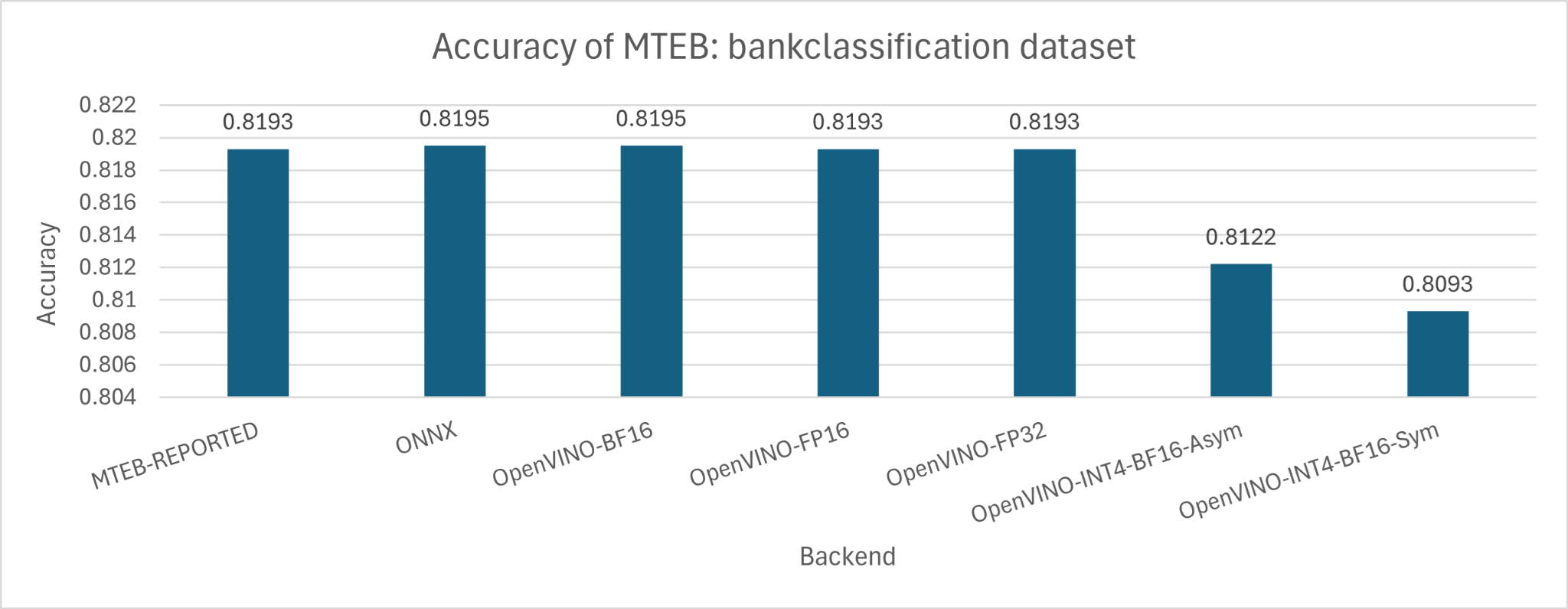
Figure 8: The accuracy of embedding model in bankclassification dataset of MTEB benchmark.
Quick Start
Launch the OpenVINO instance through docker image:
#!/bin/bash
port=7997
model1=EmbeddedLLM/bge-m3-int4-ov
volume=$PWD/data
docker run -it \
-v $volume:/app/.cache \
-p $port:$port \
--entrypoint /bin/bash \
ghcr.io/embeddedllm/infinity-intel:optimum-intel-cpu-openvino-2024.5 \
-c "source /app/.venv/bin/activate && infinity_emb v2 --port $port --model-id $model1 --model-warmup --device openvino --engine optimum"NOTE: It will automatically quantize the embedding model using weight only INT4 Asymmetrical quantization if the model repo does not contain the OpenVINO model weight.
Benefits for Users
The performance gains achieved by leveraging Intel Xeon CPUs and OpenVINO translate into tangible benefits for JamAI Base users across different domains:
- Enhanced JamAI Base Experience: Faster embedding computation leads to a more responsive and efficient JamAI Base experience. Knowledge bases can be built more quickly, and complex queries can be answered with minimal latency. This allows users to seamlessly integrate AI into their workflows and gain insights faster.
- Cost Savings: By utilizing existing CPU infrastructure, JamAI Base users can avoid the need for expensive GPUs, leading to significant cost reductions. This makes powerful AI capabilities more accessible to businesses of all sizes, including startups and smaller organizations.
- Scalability: The ability to scale embedding workloads efficiently on CPUs ensures that JamAI Base can handle the growing data demands of modern organizations. As knowledge bases expand, users can rely on the platform to maintain its performance and responsiveness.
- Accelerated Time-to-Value: With faster embedding computation, users can deploy AI solutions more rapidly and start realizing value sooner. This accelerates the process of gaining insights, automating tasks, and making data-driven decisions.
Conclusion
The journey of JamAI Base towards CPU-powered embedding models highlights a crucial shift in the AI landscape. By harnessing the power of Intel Xeon CPUs and OpenVINO, JamAI Base delivers a compelling combination of performance, efficiency, and cost-effectiveness. This approach democratizes access to powerful AI capabilities, making it easier for organizations of all sizes to leverage AI for transformative outcomes.
As AI continues to evolve, we can expect even greater advancements in CPU performance and optimization tools. This will further enhance the capabilities of platforms like JamAI Base, unlocking new possibilities for AI-driven innovation.
Ready to experience the power of AI simplified? Visit the JamAI Base website to learn more and try out the platform for yourself. Discover how you can harness the power of LLMs and build intelligent applications with the ease of a spreadsheet.
Appendix
Quantization command used in this blog post:
To get OpenVINO with INT4 Weight Only Quantization (Symmetrical) with BF16 Inference
optimum-cli export openvino --model BAAI/bge-m3 --task feature-extraction --weight-format int4 --library transformers --sym --trust-remote-code /home/devcloud/hf_models/ovms-embeddings/baai-bge-m3-optimum-convert-sym-int4To get OpenVINO with INT4 Weight Only Quantization (Asymmetrical) with BF16 Inference
optimum-cli export openvino --model BAAI/bge-m3 --task feature-extraction --weight-format int4 --library transformers --trust-remote-code /home/devcloud/hf_models/ovms-embeddings/baai-bge-m3-optimum-convert-int4To get ONNX INT8 Weight Only Quantization
# download the weight
HF_HUB_ENABLE_HF_TRANSFER=True huggingface-cli download BAAI/bge-m3
optimum-cli onnxruntime quantize --onnx_model <path/to/models–BAAI_bge-m3>/onnx --output ./quantized_baai-bge-m3-avx512_vnni-qmodel/ --avx512_vnniHow to get INT4 weight only quantized OpenVINO model manually?
Make sure you have installed OpenVINO 2024.5 for the best performance (At the point of writing this blogpost, OpenVINO 2024.5 is offer through nightly package)
pip install openvino==2024.5.0For the new embedding models that have not been quantized. You can use the following command template to quantize the embedding models into OpenVINO with INT4 Weight Only Quantization (Asymmetrical).
optimum-cli export openvino --model BAAI/bge-m3 --task feature-extraction --weight-format int4 --library transformers --trust-remote-code <path/to//hf_models/ovms-embeddings/baai-bge-m3-optimum-convert-int4>